Key Factors to a Successful & Sustainable Implementation of DevOps

Throughout my career, I have had the opportunity to drive and be part of DevOps implementation projects in several organizations of varying sizes (enterprises, tech startups) and at different levels of IT maturity. I have witnessed success stories and observed a lot more failures.
In this article, I would like to share my retrospective view of what I think are the critical ingredients required for a successful and sustainable implementation of DevOps. I would like to emphasize the sustainability aspect here because while it is challenging to have DevOps implemented successfully in an organization, it is much harder to sustain them when you lack any of the key factors that I am about to discuss. Each of these factors deserves an article on their own which I am hoping to deep-dive into each of them in my next articles to come.
Now, let’s dive right in!
Immutable Infrastructure
You must have achieved a high level of immutability on your IT services as a whole, in which the state can only be altered in an automated fashion without any direct human intervention. There is no business of tinkering with services after it has been provisioned, rather you will focus on tearing it down and rebuilding them with new configurations.
You have in place a set of defined automated processes to interact with your infrastructure, and there are no exceptions to the rule. For efficiency, you also have standardized deployment patterns and a set of infrastructure templates (as code) ready to be provisioned such as operating systems and the baseline configurations.
You have the means to audit and trace every change that takes place. In other words, when things change in your production environment, for instance, everyone in the team knows of how, who, and when that change was executed. Ideally, the role of DevOps engineers should only be to build facilities for the development team to self-serve deployments themselves. Having highly regulated and controlled access to target infrastructure is critical in ensuring high levels of certainty and integrity.
In the domain of Infrastructure as Code (IAC), we have many capable platforms in the market and one of them is Terraform. My colleague, Fajri wrote an interesting article on getting started with Terraform.
Observability
We often come across this statement: “You can’t improve what you can’t measure”. You must have in place effective ways of monitoring important metrics generated by your tools and services that your team has deployed. In addition to that, you also have made these data easily accessible to everyone in the team by presenting them visually as much as possible, thus increasing the level of observability. This is usually done in the form of dashboards composed of various charts that better facilitate the consumption of the data collected by your monitoring tools.
In my opinion, this is the ultimate objective and the main motivation behind DevOps. When you achieve a high level of automation in your software services delivery and operations, you can then rely on data and hard facts at every stage of your pipeline, rather than having to depend on assumptions on how and why an event took place. The continuous cycle of learning and re-calibrating your tools and release processes to achieve maximum efficiency would only be possible if you are able to identify areas of improvement based on a true picture of your current environment.
Branching Strategy
There are many schools of thought around the branching strategy. CI purists will suggest that you should work on your master branch directly (trunk-based development) and avoid working in isolation in feature branches, whereas the proponents of feature branch-ers will argue that keeping unfinished work away in feature branches should not be merged master until it is safe. There is a very useful guide by Martin Fowler on this topic, one of the most prominent thought leaders on CI/CD.
The reality is that there is no one-size-fits-all solution. The branching strategy for your team is dependent on many factors. Some of the factors include team structure, codebase size and structure, developer competency level and skillsets, product management strategy, the delivery model just to name a few.
No matter which branching strategy you chose to adopt, you must have a situation where the master branch is updated frequently and stays up-to-date most of the time. Why is this critical you ask? Because without this, developers lose the opportunity to obtain instant feedback to the code that they have just committed to the repository. The longer it takes for a code change to be merged into the master, the longer it will take for the developer to debug and fix any errors. To illustrate this point, please look at these 2 scenarios below:
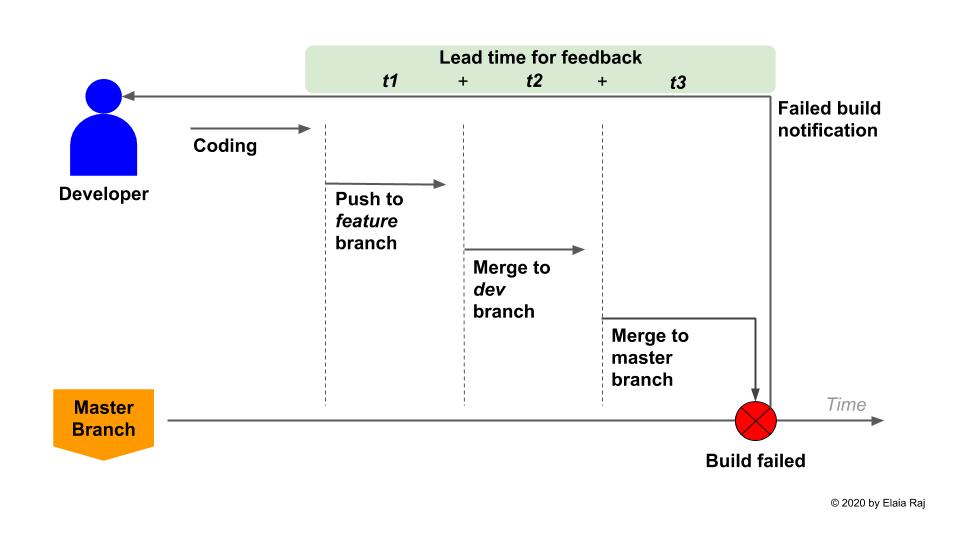
Teams that do not update the master branch frequently wait for a longer time for feedback if a change is causing any issues in the master branch.
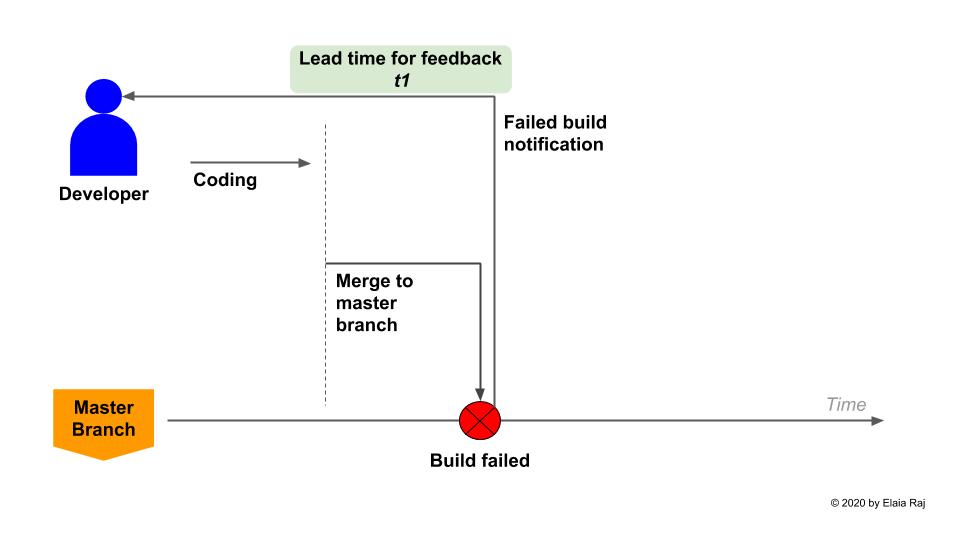
Teams that frequently/directly update the master branch get instant feedback if a change is breaking the product.
Secondly, frequently and incrementally updating the master branch prevents major merge conflicts that may require a much longer time to resolve. Furthermore, for us as human beings, recollecting a task that was done an hour ago is a much easier process if compared to trying to remember a task that was completed 2 weeks ago. Naturally, this is going to require more time and effort for the developer to fix the issue, especially when he/she could have already moved on working on other tasks.
Maintainable and Testable Codebase
Robert C. Martin in his book “Clean Code", speaks about the importance of ensuring that your code can communicate with the reader. If a developer looks at a piece of code for the first time, he/she should be able to understand easily what the code is intending to achieve. Easily comprehensible code increases the maintainability of your codebase i.e. “when it is easy to understand then it will be quite easy to change”.
You must have standards and support in place for your developers to produce clean and legible code. Maintainability becomes very crucial in a DevOps setting because the velocity of events taking place is much higher compared to traditional software development processes. Events include instances of code pushes and build failures. We discussed earlier that with the right branching strategy, you are enabling the developers to receive instant feedback. The downside to that is that the master branch will experience a series of small breaks frequently. When this happens, the developers must be able to fix the issue quickly. Naturally, if the code is easy to read and comprehend, then it takes significantly less effort and time to fix it.
To successfully implement DevOps in your organization, your codebase must be automatically testable. When your code is test-ready and you have necessary test scripts written to exercise as many of these lines of code, you achieve high code coverage. High code coverage is critical because, in DevOps, you rely heavily on automated test results before determining if the particular build is successful or not. Code coverage of 80% or nearing that number makes your tests reliable. For new projects, it is highly recommended to think about code coverage very early on as it becomes increasingly difficult to improve them after-the-fact.
Writing testable code requires a very different approach when writing code. You must have coding conventions that comply with design principles and patterns that facilitate testability. I will delve deeper into this topic in a separate article as it is too vast of a subject to be discussed here.
State of Testing
According to “The DevOps Handbook” by Gene Kim et al., one of the “3 Ways of DevOps” is “fast feedback”. We want to be able to know at the earliest opportunity, whether a change that is introduced into our product codebase is working as it should, and is not breaking any other parts of the product. Basically, the idea is that the earlier we identify an issue, the easier it is to fix. One way to achieve this is by automating the testing phase so that they can be executed fast and repetitively. However, implementing automated test tools and having a team capable of authoring automated test scripts alone are insufficient.
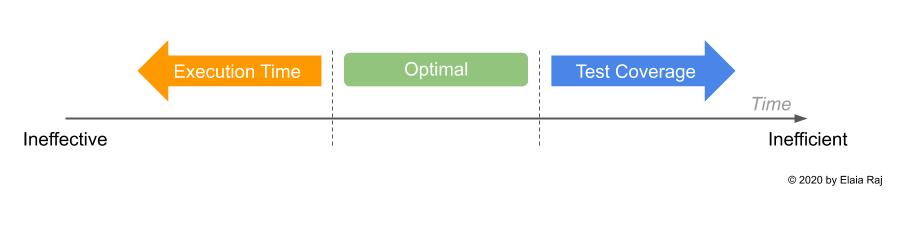
As per the illustration above, you must have achieved the right balance with your automated testing solutions so that they are both fast to execute and they provide a high level of coverage. As you can imagine, this is no easy feat and understandably, this is where most teams abandon the idea of automated testing (and DevOps entirely) and rely on good old manual testing. However, specific strategies can be employed to address this challenge. This includes making use of stubs, mocks and fakes in unit testing, creating mock services in place of external service calls for functional testing, and selectively executing tests for critical functionalities of the product.
The second challenge when it comes to automated testing is the maintenance aspect of it. The change to our codebase occurs daily. This is more so for a product that is being actively developed or for early-stage startups who are at the experimenting stage. In this situation, there is a high possibility that many of your tests will break. It is also typical to see that tasks to update the test scripts often get pushed aside when the team works on rolling out a feature urgently, with hopes that we will get to it later. But more often than not, that “later” never comes, incurring more technical debt. When automated test results can no longer be relied upon we again turn to manual testing. You must have processes in place that the entire test suite for the product stays up-to-date at all times, including measures in place to cater to any exceptions that are sometimes inevitable i.e. cutting corners.
Team/Organizational Culture
DevOps requires buy-in and commitment from the leadership and the entire team. Buy-in can only be obtained if they understand what it means to them and how it can help them do a better job. In a workplace, it is natural for employees to aspire to deliver excellent results and in turn get recognized by their bosses for their great work. If the team and the leadership do not believe DevOps will help them get there, then you will be fighting a lonely battle.
In a traditional corporate culture, the first order of the day when things go wrong is to find and penalize the person or the department responsible for the mishap. Such a mindset will hamper your DevOps implementation. You must have created a safe, blame-less environment for your team to operate objectively without fear of being singled-out. The team focuses on identifying the root cause by examining the telemetric data points with the objective of learning and improving, rather than finger-pointing. I cannot emphasize enough the importance of moving away from punitive measures to rewarding the team for a great job done.
One real-life example is Netflix. They are pushing the envelope to areas beyond the standard DevOps practices. This is only possible when the team is obsessed with service excellence and the culture of the organization that fuels the continuous improvement mindset.
A Real Need
The final piece and perhaps the most important consideration that will determine the success of DevOps in your project or in your organization is that you have a real business need for DevOps. It may sound like a simple and obvious decision to make but unfortunately, the IT world is full of noise. Every technology vendor will tell you that you absolutely need certain processes or technologies to remain relevant, but is it really so?
Let’s be real. Not all software services in the market require agility. If you only have 2 releases per year and the software has already reached its maturity, then spending your effort in implementing DevOps makes no business sense. In some cases, the software cannot be rolled out quickly nor autonomously especially when dealing with services in highly regulated industries such as defense.
Of course one can argue that by doing things efficiently, it frees up the team’s time to work on something more productive. I agree with that, but the question we should ask is at what cost? How much time and resources are required to achieve and maintain that agility? If you’re working for a for-profit organization, then that time and money can be spent elsewhere that can assure better returns of your investment. From my observations, even when you have successfully implemented DevOps, but if there is no real need, it dies off naturally.
Conclusion
If I could summarize perhaps from a high-level perspective, the success of your DevOps implementation depends on your ability to achieve the following:
Sustainability - You have the necessary processes, team, and toolsets in place to be able to continuously operate DevOps practices for an extended period.
Consistency - You have standards, policies, and procedures clearly defined and adhered to.
Persistency - You have instilled discipline among team members and have employed well-thought-out active control measures that prohibit unconventional and old “workaround” habits
Excellence - You have assembled a highly driven team that strives for continuous improvement